Supermicro's Twin: Two nodes and 16 cores in 1U
by Johan De Gelas on May 28, 2007 12:01 AM EST- Posted in
- IT Computing
Network Load Balancing
It is pretty clear that we can not test the Supermicro 1U Twin in a conventional manner. Testing one node alone doesn't make sense: who care if it is 1-2% faster or slower than a typical Intel 5000p chipset based server? So we decided to use Windows 2003 Network Load Balancing or software load balancing. NLB is used mostly for splitting the load of heavy web-based traffic over several servers to improve response times, throughput and more importantly, availability. Each node sends a heartbeat signal. If a host fails and stops emitting heartbeats, the other nodes will remove it from their NLB cluster information, and although a few seconds of network traffic will be lost, the website remains available. What is even better is the fact that NLB, due to the relatively simple distributed filtering algorithm on each node, puts very little load on the CPUs of the node. The heartbeat messages also consume very little bandwidth. Testing with a fast Ethernet switch instead of our usual Gigabit Ethernet switch didn't result in any significant performance loss, whether we talk about response time (ms) or throughput (URLs served per second).
With four and up to eight CPUs per node, it takes a while before the NLB cluster becomes fully loaded, as you can see at the picture below.

Web server measurements are a little harder to interpret than other tests, as you always have two measurements: response time and throughput. Theoretically, you could set a "still acceptable" maximum response time and measure how many requests the system can respond to without breaking this limit. However, in reality it is almost impossible to test this way, as we simulate a number of simultaneous users which send requests and then measure both response time and throughput. Each simultaneous user takes about one second to send a new request. Notice that the number of simultaneous user is not equal to the total number of users. One hundred simultaneous users may well mean that there are 20 users constantly clicking to get new information while 240 others are clicking and typing every 3 seconds.
Another problem is of course that in reality you never want your web server to be at 100% CPU load. For our academic research, we track tens of different parameters, including CPU load. For a report such as this one, this would mean however that you have to wade through massive tables to get an idea how the different systems compare. Therefore, we decide to pick out a request rate at which all systems where maxed out, to give an idea of the maximum throughput and the associated latency. In the graphics below, 200 simultaneous users torture the MCS web application requesting one URL every second.
The single node tests are represented by the lightly colored graphs, the darker graphs represent our measurement in NLB mode (2 nodes). We were only able to get four Xeon E5320 (quad core 1.86 GHz Intel Core architecture) processors for this article, unfortunately; it would have been nice to test with various other CPUs in 4-way configurations, but sometimes you have to take what you can get.
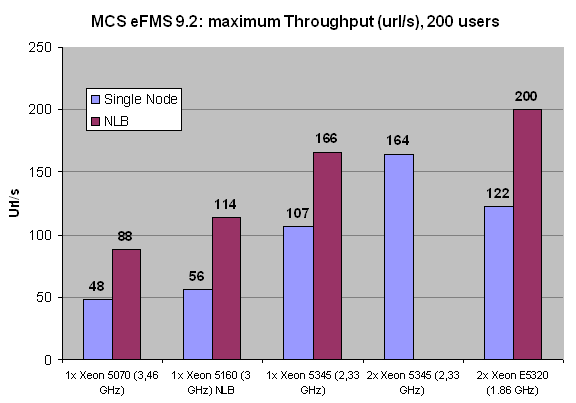
Notice that two CPUs connected by NLB and thus Gigabit Ethernet are not slower than two CPUs connected by the FSB. In other words, two nodes with one CPU per node are not slower than two CPUs in a single node. The most likely explanation is that the overhead of communicating over a TCP/IP Ethernet connection is offset by the higher amount of bandwidth that each CPU in the node has available. From the numbers above we may conclude that NLB scales very well: adding a second node increases the throughput by 60 to 100%. Scaling decreases as we increase the CPU power and the number of cores which is no surprise, as the latency of the Gigabit connection between the nodes starts to become more important. To obtain better scaling, we would probably have to use an InfiniBand connection but for this type of application that seems a bit like overkill.
Also note that 200 users means 200 simultaneous users which may translate - depending on the usage model of the client - to a few thousands of real active users in a day. The only configuration that can sustain this is the NLB configuration: in reality it could serve about 225 simultaneous users at one URL/s, but as we only asked for 200, it served up 200.
To understand this better, let us see what the corresponding response time is. Remember that this is not the typical response time of the application, but the response you get from an overloaded server. Only the 16 Xeon E5320 cores were capable of delivering more than 200 URL/s (about 225), while the other configurations had to work with a backlog.
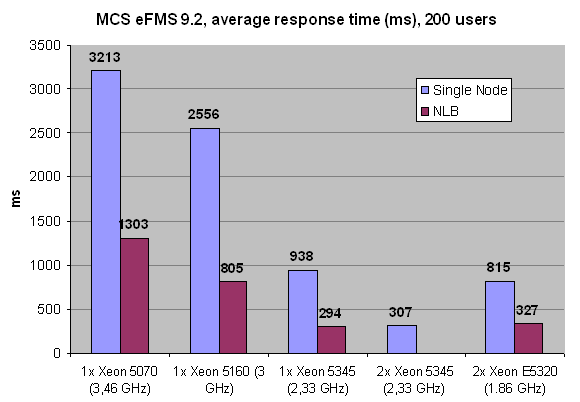
It is a bit extreme, but it gives a very good idea of what happens if you overload a server: response times increase almost exponentially. When we tested with 100 users, our dual Xeon E5320 (1.86 GHz, four cores in one node) provided a response time of about 120 ms on average per URL - measured across about 40 different URLs - and so did the same configuration in NLB (two nodes). A Xeon 5160 in each node in NLB responded in 145 ms, as the demanded throughput was much closer to its maximum of 114 ms. Now take a look at the measured response times at 200 URL/s.
The Xeon Dempsey 5070 (dual core 3.46 GHz 2MB NetBurst architecture) is only capable of sustaining half the user requests we demand from it, and the result is a 10X higher response time than our two node 16 core NLB server, or almost 30X higher than the minimum response time. Our quad Xeon 1.86 in NLB was capable of a response time of 327 ms, almost 3X higher than the lowest measured response time at 100 URL/s. So we conclude that pushing a web server to 90% of its maximum will result in a ~3X higher response time. This clearly shows that you should size your web server to work at about 60%, and no peak should go beyond 90%. Overload your web server with twice the traffic it can handle, and you'll be "rewarded" with response times that get 30X higher than the minimum necessary response time.
It is pretty clear that we can not test the Supermicro 1U Twin in a conventional manner. Testing one node alone doesn't make sense: who care if it is 1-2% faster or slower than a typical Intel 5000p chipset based server? So we decided to use Windows 2003 Network Load Balancing or software load balancing. NLB is used mostly for splitting the load of heavy web-based traffic over several servers to improve response times, throughput and more importantly, availability. Each node sends a heartbeat signal. If a host fails and stops emitting heartbeats, the other nodes will remove it from their NLB cluster information, and although a few seconds of network traffic will be lost, the website remains available. What is even better is the fact that NLB, due to the relatively simple distributed filtering algorithm on each node, puts very little load on the CPUs of the node. The heartbeat messages also consume very little bandwidth. Testing with a fast Ethernet switch instead of our usual Gigabit Ethernet switch didn't result in any significant performance loss, whether we talk about response time (ms) or throughput (URLs served per second).
With four and up to eight CPUs per node, it takes a while before the NLB cluster becomes fully loaded, as you can see at the picture below.
Web server measurements are a little harder to interpret than other tests, as you always have two measurements: response time and throughput. Theoretically, you could set a "still acceptable" maximum response time and measure how many requests the system can respond to without breaking this limit. However, in reality it is almost impossible to test this way, as we simulate a number of simultaneous users which send requests and then measure both response time and throughput. Each simultaneous user takes about one second to send a new request. Notice that the number of simultaneous user is not equal to the total number of users. One hundred simultaneous users may well mean that there are 20 users constantly clicking to get new information while 240 others are clicking and typing every 3 seconds.
Another problem is of course that in reality you never want your web server to be at 100% CPU load. For our academic research, we track tens of different parameters, including CPU load. For a report such as this one, this would mean however that you have to wade through massive tables to get an idea how the different systems compare. Therefore, we decide to pick out a request rate at which all systems where maxed out, to give an idea of the maximum throughput and the associated latency. In the graphics below, 200 simultaneous users torture the MCS web application requesting one URL every second.
The single node tests are represented by the lightly colored graphs, the darker graphs represent our measurement in NLB mode (2 nodes). We were only able to get four Xeon E5320 (quad core 1.86 GHz Intel Core architecture) processors for this article, unfortunately; it would have been nice to test with various other CPUs in 4-way configurations, but sometimes you have to take what you can get.
Notice that two CPUs connected by NLB and thus Gigabit Ethernet are not slower than two CPUs connected by the FSB. In other words, two nodes with one CPU per node are not slower than two CPUs in a single node. The most likely explanation is that the overhead of communicating over a TCP/IP Ethernet connection is offset by the higher amount of bandwidth that each CPU in the node has available. From the numbers above we may conclude that NLB scales very well: adding a second node increases the throughput by 60 to 100%. Scaling decreases as we increase the CPU power and the number of cores which is no surprise, as the latency of the Gigabit connection between the nodes starts to become more important. To obtain better scaling, we would probably have to use an InfiniBand connection but for this type of application that seems a bit like overkill.
Also note that 200 users means 200 simultaneous users which may translate - depending on the usage model of the client - to a few thousands of real active users in a day. The only configuration that can sustain this is the NLB configuration: in reality it could serve about 225 simultaneous users at one URL/s, but as we only asked for 200, it served up 200.
To understand this better, let us see what the corresponding response time is. Remember that this is not the typical response time of the application, but the response you get from an overloaded server. Only the 16 Xeon E5320 cores were capable of delivering more than 200 URL/s (about 225), while the other configurations had to work with a backlog.
It is a bit extreme, but it gives a very good idea of what happens if you overload a server: response times increase almost exponentially. When we tested with 100 users, our dual Xeon E5320 (1.86 GHz, four cores in one node) provided a response time of about 120 ms on average per URL - measured across about 40 different URLs - and so did the same configuration in NLB (two nodes). A Xeon 5160 in each node in NLB responded in 145 ms, as the demanded throughput was much closer to its maximum of 114 ms. Now take a look at the measured response times at 200 URL/s.
The Xeon Dempsey 5070 (dual core 3.46 GHz 2MB NetBurst architecture) is only capable of sustaining half the user requests we demand from it, and the result is a 10X higher response time than our two node 16 core NLB server, or almost 30X higher than the minimum response time. Our quad Xeon 1.86 in NLB was capable of a response time of 327 ms, almost 3X higher than the lowest measured response time at 100 URL/s. So we conclude that pushing a web server to 90% of its maximum will result in a ~3X higher response time. This clearly shows that you should size your web server to work at about 60%, and no peak should go beyond 90%. Overload your web server with twice the traffic it can handle, and you'll be "rewarded" with response times that get 30X higher than the minimum necessary response time.








28 Comments
View All Comments
JohanAnandtech - Monday, May 28, 2007 - link
Those DIMM slots are empty :-)yacoub - Monday, May 28, 2007 - link
ohhh hahah thought they were filled with black DIMMs :Dyacoub - Monday, May 28, 2007 - link
Also on page 8:You should remove that first comma. It was throwing me off because the way it reads it sounds like the 2U servers save about 130W but then you get to the end of the sentence and realize you mean "in comparison with 2U servers, we save about 130W or about 30% thanks to Twin 1U". You could also say "Compared with 2U servers, we save..." to make the sentence even more clear.
Thanks for an awesome article, btw. It's nice to see these server articles from time to time, especially when they cover a product that appears to offer a solid TCO and strong comparative with the competition from big names like Dell.
JohanAnandtech - Monday, May 28, 2007 - link
Fixed! Good pointgouyou - Monday, May 28, 2007 - link
The part about infiniband's performance much better as you increase the number of core is really misleading.The graph is mixing core and nodes, so you cannot tell anything. We are in an era where a server has 8 cores: the scaling is completely different as it will depend less on the network. BTW, is the graph made for single core servers ? dual cores ?
MrSpadge - Monday, May 28, 2007 - link
Gouyou, there's a link called "this article" in the part on InfiniBand which answers your question. In the original article you can read that they used dual 3 GHz Woodcrests.What's interesting is that the difference between InfiniBand and GigE is actually more pronounced for the dual core Woodcrests compared with single core 3.4 GHz P4s (at 16 nodes). The explanation given is that the faster dual core CPUs need more communication to sustain performance. So it seems like their algorithm uses no locality optimizations to exploit the much faster communication within a node.
@BitJunkie: I second your comment, very nice article!
MrS
BitJunkie - Monday, May 28, 2007 - link
Nice article, I'm most impressed by the breadth and the detail you drilled in to - also the clarity with which you presented your thinking / results. It's always good to be stretched and great example of how to approach things in structured logical way.Don't mind the "it's an enthusiast site" comments. Some people will be stepping outside their comfort zone with this and won't thank you for it ;)
JohanAnandtech - Monday, May 28, 2007 - link
Thanks, very encouraging comment.And I guess it doesn't hurt the "enthusiast" is reminded that "pcs" can also be fascinating in another role than "Hardcore gaming machine" :-). Many of my students need the same reminder: being an ITer is more than booting Windows and your favorite game. My 2-year old daughter can do that ;-)
yyrkoon - Monday, May 28, 2007 - link
It is however nice to learn about InfiniBand. This is a technology I have been interrested in for a while now, and was under the impression was not going to be implemented until PCIe v2.0 (maybe I missed something here).I would still rather see this technology in the desktop class PC, and if this is yet another enterprise driven technology, then people such as myself, who were hoping to use it for decent home networking(remote storage) are once again, left out in the cold.
yyrkoon - Monday, May 28, 2007 - link
And I am sure every gamer out there knows what iSCSI *is* . . .
Even in 'IT' a 16 core 1U rack is a specialty system, and while they may be semi common in the load balancing/failover scenario(or maybe even used extensively in paralell processing, yes, and even more possible uses . . .), they are still not all that common comparred to the 'standard' server. Recently, a person that I know deployed 40k desktops/ 30k servers for a large company, and would'nt you know it, not one had more than 4 cores . . . and I have personally contracted work from TV/Radio stations(and even the odd small ISP), and outside of the odd 'Toaster', most machines in these places barely use 1 core.
I too also find technologies such as 802.3 ad link aggregation, iSCSI, AoE, etc interresting, and sometimes like playing around with things like openMosix, the latest /hottest Linux Distro, but at the end of the day, other than experimentation, these things typically do not entertain me. Most of the above, and many other technologies for me, are just a means to an end, not entertainment.
Maybe it is enjoyable staring at a machine of this type, not being able to use it to its full potential outside of the work place ? Personally I would not know, and honestly I really do not care, but if this is the case, perhaps you need to take notice of your 2 year old daughter, and relax once in a while.
The point here ? The point being: pehaps *this* 'gamer' you speak of knows a good bit more about 'IT' than you give him credit for, and maybe even makes a fair amount of cash at the end of the day while doing so. Or maybe I am a *real* hardware enthusiast, who would rather be reading about technology, instead of reading yet another 'product review'. Especially since any person worth their paygrade in IT should already know how this system (or anything like) is going to perform beforehand.